Парсинг сайтов через питон
Устанавливаем и импортируем библиотеки в питон
pip install requests
pip install pandas
import requests
from bs4 import BeautifulSoup
import pandas as pd
from time import sleepПеременной url присваиваем ссылку на страницу кинопоиска, в переменную r результат гет запроса к этой странице
url = "https://www.kinopoisk.ru/s/type/film/list/1/find/%F1%E5%EA%F1/"
r = requests.get(url)
Переведем содержимое страницы в формат кода
soup = BeautifulSoup(r.text, "lxml")
---Google-Chrome-2021-01-21-13.01.03.jpg)
russian_name = soup.find('div',class_ = "element").find('div', class_ = "info").find('a', class_ = "js-serp-metrika").text
russian_name
original_name = soup.find('div',class_ = "element").find('span', class_ = "gray").text
original_name
year = soup.find('div',class_ = "element").find('span', class_ = "year").text
year
kinopoisk = soup.find('div',class_ = "element").find('div', class_ = "rating").text
kinopoisk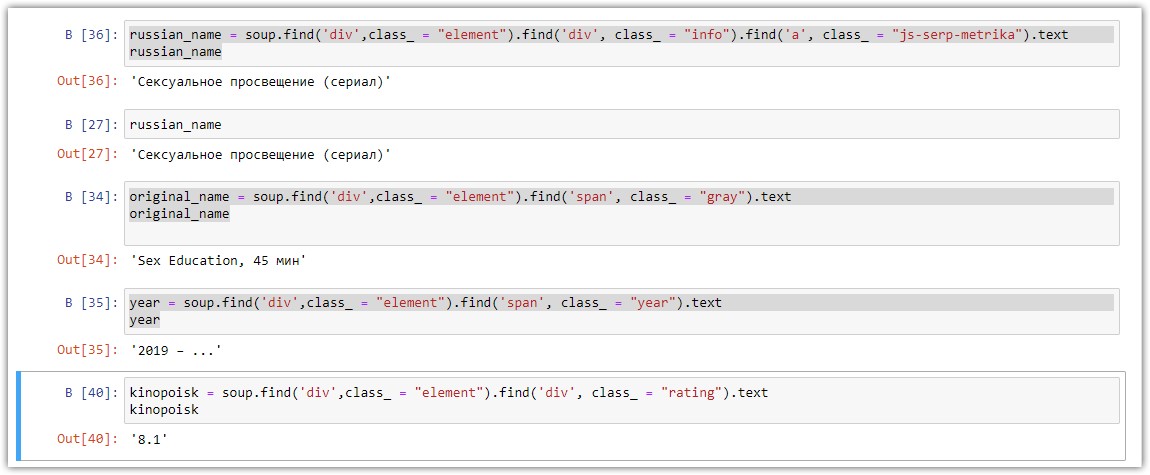
Находим контейнер с кусочком кода и генерируем ссылку на фильм
link = "https://www.kinopoisk.ru" +soup.find('div',class_ = "element").find('div', class_ = "info").find('a').get("data-url")
link

Можно составить код, который сделает таблицу, содержащую все фильмы с данной таблицы
data = []
films =soup.findAll("div",class_ = "element")
for film in films:
russian_name = film.find('div', class_ = "info").find('a', class_ = "js-serp-metrika").text
original_name = film.find('span', class_ = "gray").text
try:
year = film.find('span', class_ = "year").text
except:
year = ""
try:
kinopoisk = film.find('div', class_ = "rating").text
except:
kinopoisk = ""
link = "https://www.kinopoisk.ru" +film.find('div', class_ = "info").find('a').get("data-url")
#print (russian_name)
#print (original_name)
#print (year)
#print (kinopoisk)
#print (link)
data.append([russian_name, original_name,year,kinopoisk,link ])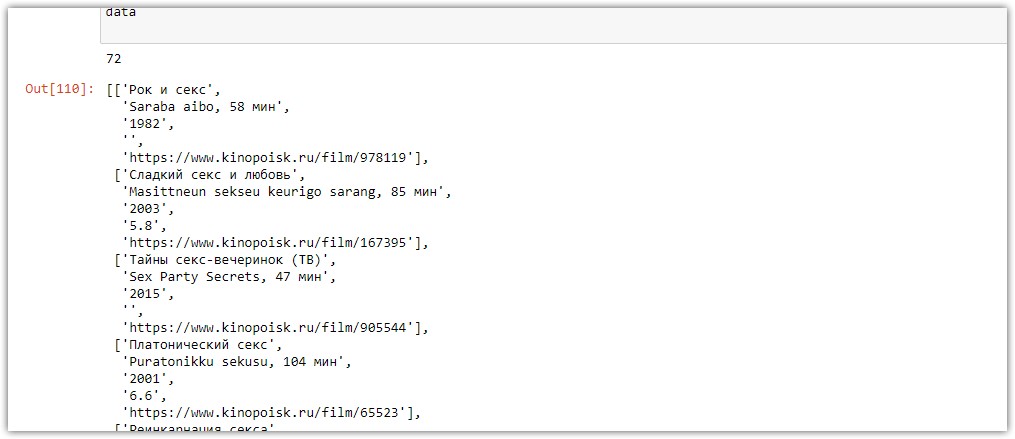
Мы можем собрать все фильмы с одной страницы. Теперь нужно сделать цикл для сбора со всех страниц данного раздела. В этом разделе 11 страниц, значит нужен цикл для формирования списка страниц
for page in range(1,12):
url = f"https://www.kinopoisk.ru/s/type/film/list/1/find/%F1%E5%EA%F1/order/relevant/page/{str(page)}/"
print(url)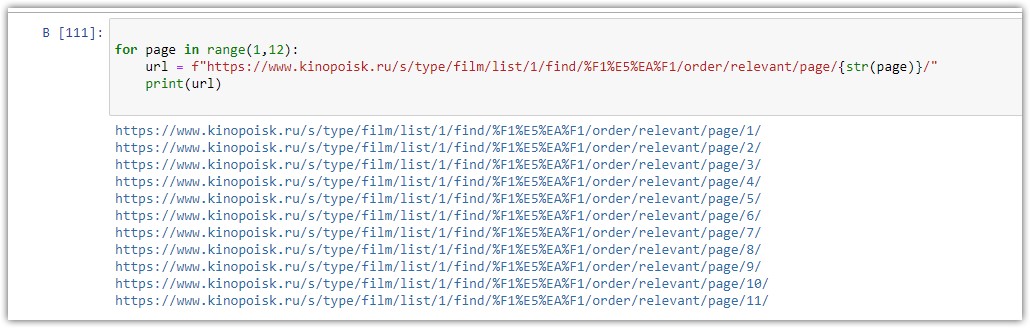
Теперь можно дополнить весь код. Не забываем про слип, так как на многих сайтах стоит защита от парсинга
data = []
for page in range(1,12):
url = f"https://www.kinopoisk.ru/s/type/film/list/1/find/%F1%E5%EA%F1/order/relevant/page/{str(page)}/"
print(url)
r = requests.get(url)
sleep(40)
soup = BeautifulSoup(r.text, "lxml")
films = soup.findAll("div", class_ ="element")
for film in films:
russian_name = film.find("div", class_="info").find("a").text
# print(russian_name)
original_name = film.find("div", class_="info").find("span", class_="gray").text
year = film.find("span", class_="year").text
try:
year = film.find("div", class_= "span").text
except:
year = ""
try:
rate = film.find("div", class_= "rating").text
except:
rate = ""
link = "https://www.kinopoisk.ru"+film.find("div", class_="info").find("a").get("data-url")
data.append([russian_name, original_name, year, link])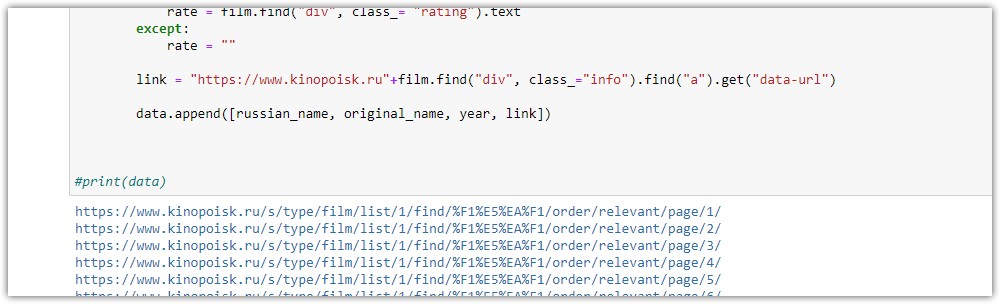
Делаем заголовки таблицы и выгружаем в файл csv
header = ['russian_name', 'original_name', 'year', 'link']
df = pd.DataFrame(data, columns = header)
df.head()
df.to_csv("d:\data_kino.csv")
Можно и в питоне получить список всех ссылок на фильмы, работая с таблицей
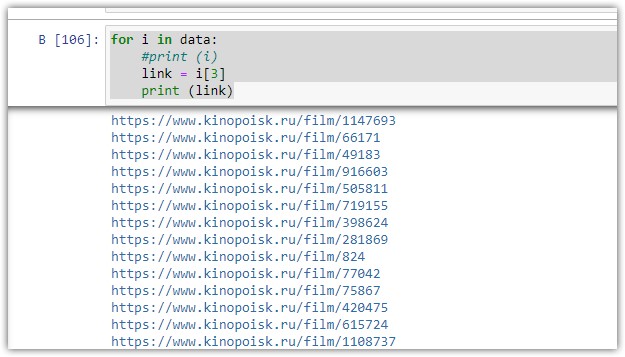
for i in data:
#print (i)
link = i[3]
print (link)