
Парсинг сайтов через питон модулем selenium
Работа идет через модуль selenium, для него нужно скачать Chrome driver и браузер Chrome.
Важно чтобы версия браузера и Chrome driver была одна и та же
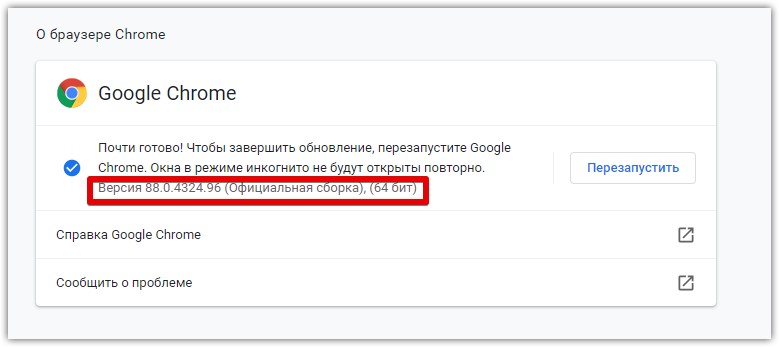

Чтобы точно быть уверенным, что все работает установите библиотеку selenium, импортируйте ее и запустите браузер через хром драйвер.
pip install selenium
from selenium.webdriver import Chrome
browser = Chrome ("d:\del\chromedriver_win32\chromedriver.exe")

В тестовом браузере будут выполнятся все команды.
Импортируем необходимые библиотеки
from selenium.webdriver import Chrome
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait as wait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import NoSuchElementException
from bs4 import BeautifulSoup
from time import sleepПереход на сайт
url = "https://bus.gov.ru/registry"
browser.get(url)
Нужно ввести в строке поиска «онкологический диспансер»
Способ 1
input_el = browser.find_element_by_tag_name("input")
input_el.send_keys("онкологический диспансер")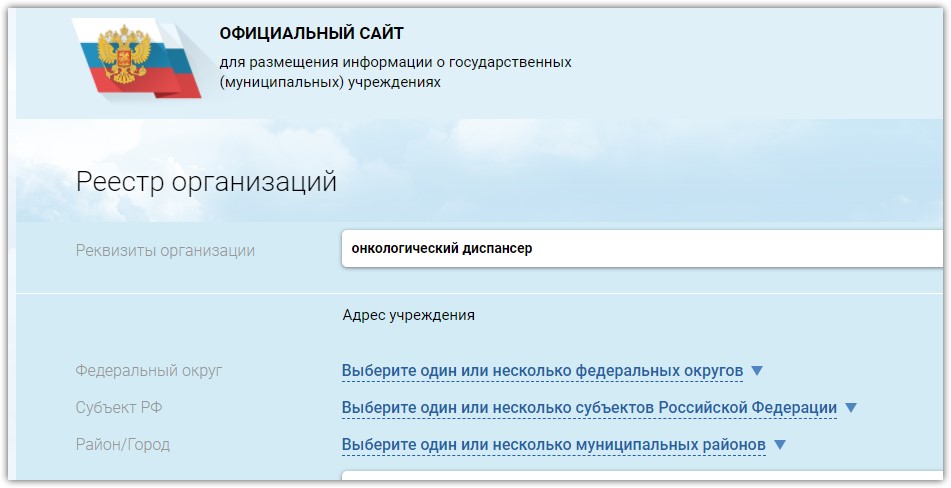
Нажать энтер или кнопку найти.
Нажатие кнопки энтер:
input_el.send_keys(Keys.ENTER)Нажатие кнопки найти:
browser.find_element_by_xpath("/html/body/div[2]/ui-view/form/div[2]/div/div[2]/div/button").click()
Дальше работаем как при простом парсинге сайта
soup = BeautifulSoup(browser.page_source, "lxml")
soup
Смотрим где содержится название учреждения и ссылка на него
soup.find ("a", class_="result__button").get("href")
soup.find("a",class_="result__title").text
Чтобы не искать по всей странице, можно оставить информацию которая нам нужна, она содержится к контейнере c классом results
orgs=soup.findAll("div",class_="result")
orgs
Обработка текущей страницы
data = []
for el in orgs:
name = el.find("a", class_="result__title").text
link = "https://bus.gov.ru/registry" + el.find("a", class_="result__button").get("href")
#print (name, link)
data.append([name,link])
data
Нужно нажимать на страницу «следующая»
next_button = browser.find_element_by_class_name("pagination__next")
next_button.click()Код нажимает на элемент с классом pagination__next
Готовый код для сбора всей информации
url = 'https://bus.gov.ru/registry'
browser.get(url)
sleep(5)
input_el = browser.find_element_by_tag_name('input')
input_el.send_keys('онкологический диспансер')
input_el.send_keys(Keys.ENTER)
sleep(5)
data = []
for i in range(10):
soup = BeautifulSoup(browser.page_source, "lxml")
orgs = soup.findAll('div', class_='result')
for el in orgs:
name = el.find('a', class_='result__title').text
link = "https://bus.gov.ru"+el.find('a', class_='result__button').get('href')
print(name, link)
data.append([name, link])
print(len(data))
try:
next_button = browser.find_element_by_class_name('pagination__next')
next_button.click()
except NoSuchElementException:
continue
sleep(6)